查询构造技巧
查询复用
由于sqala使用Scala代码管理查询构造,因此可以很容易地将几个查询的共有部分封装起来:
scala
def baseQuery = query:
from[Employee]
.join[Department]((e, d) => e.departmentId == d.id)这样,这个基础查询就可以多次使用,用于构建其他查询:
scala
val q1 = query:
baseQuery.filter((e, d) => e.name == "小黑")
val q2 = query:
baseQuery.sortBy((e, d) => d.name)但查询共用部分如果作为子查询使用,上面的代码可能会产生错误的查询语义,此时我们需要在查询封装时using QueryContext:
scala
def baseQuery(using QueryContext) =
from[Employee]而实际的查询需要在query方法中构建:
scala
val q1 = query:
baseQuery.filter(e => e.name == "小黑")
val q2 = query:
baseQuery.filter(e => e.name == baseQuery.filter(ee => e.id == 1).map(ee => ee.name))在未来的版本中,可能会利用Scala3的新特性Capture Checking来强制检查查询是否在同一个上下文中构建,但目前需要在编写复用子查询时注意不要省略using QueryContext,以防止生成错误SQL。
条件构造
除了基础的filterIf用于构造可选过滤条件外,sqala还支持更灵活的条件构造查询,比如通过不同条件使用不同的字段分组:
scala
case class Data(dim1: Int, dim2: Int, dim3: Int, measure: Int)
val dim: Int = ???
val baseQuery = query:
from[Data]
val q = if dim == 1 then
baseQuery.groupBy(d => d.dim1).map(d => (d.dim1, sum(d.measure)))
else if dim == 2 then
baseQuery.groupBy(d => d.dim2).map(d => (d.dim2, sum(d.measure)))
else
baseQuery.groupBy(d => d.dim3).map(d => (d.dim3, sum(d.measure)))提升子查询的可读性
在同一个query上下文中,我们可以将能独立运行的子查询存入变量,无需像标准SQL那样嵌套子查询,以提高可读性:
scala
val q = query:
val salaryAvg = from[Employee].map(e => avg(e.salary))
from[Employee].filter(e => e.salary > salaryAvg)显示SQL和语义分析
将查询设置为inline def,sqala就会在编译期尝试生成查询树,并进行语义分析,以便尽早发现错误:
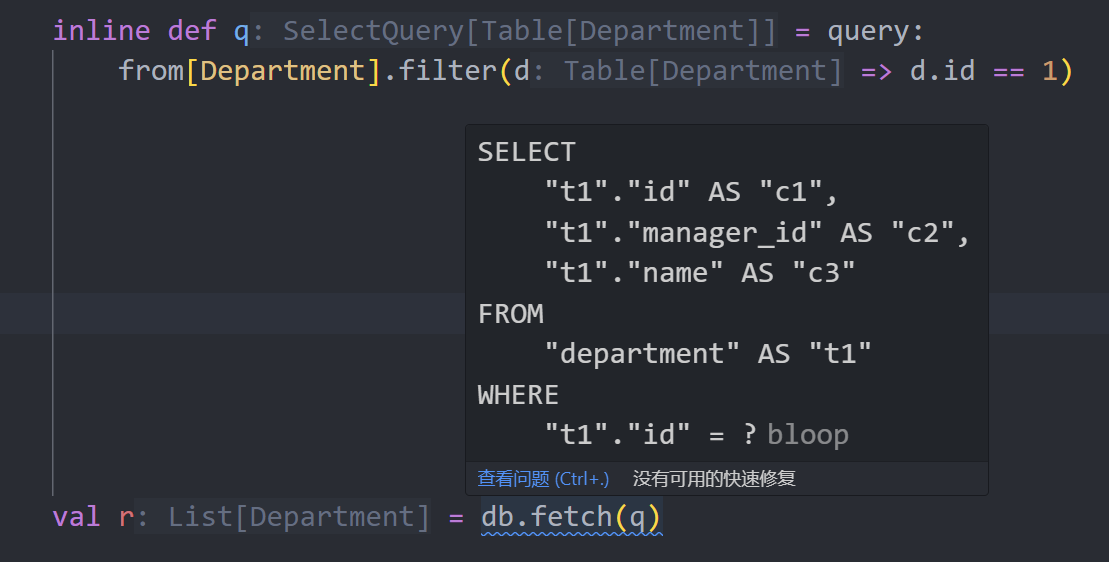
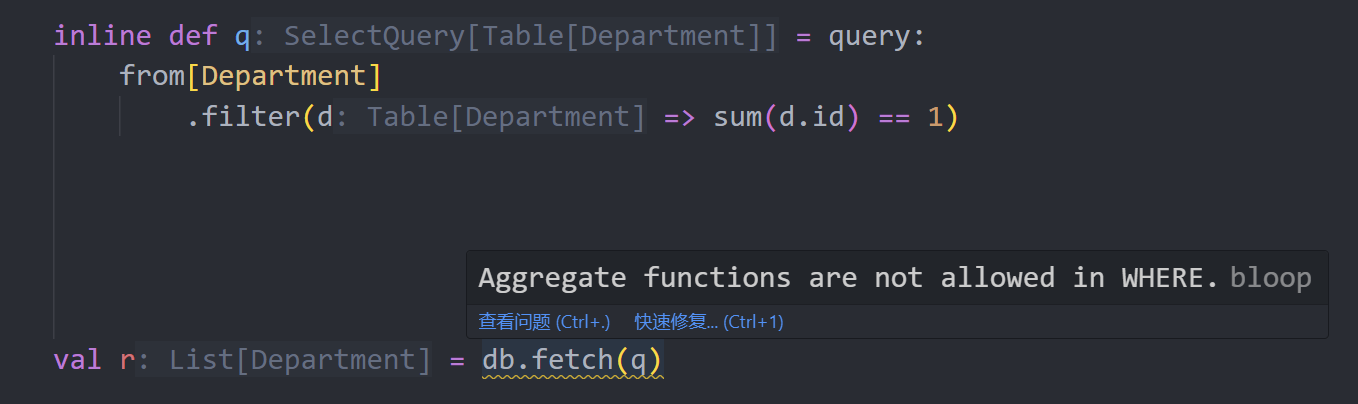
前提是查询没用用到filterIf等动态特性。